Arcanization is a large refactoring of wgpu’s internals aiming at reducing lock contention, and providing better performance when using wgpu on multiple threads. It was just merged into wgpu’s trunk branch and will be published as part of the 0.19 release scheduled for around January 17th.
A Long Journey
Before diving into the technical details, let’s have a quick look at the history of this project. The work started some time around mid 2021 with significant involvement from @pythonesque, @kvark and @cwfitzgerald. It went though multiple revisions, moving from one person to the next, until @gents83 picked it up and opened a pull request on March 30th 2023.
Fast-forward November 20th, after countless rebases, revisions and fixes by @gents83 spanning nearly 8 months, the pull request is finally merged! They tirelessly maintained this big and complex refactoring, all while the project was constantly changing and improving underneath them!
The Problem
wgpu internally stores all resources (buffers, textures, bind groups, etc.) in big contiguous arrays held by what we call the Hub.
Most of the data stored in these arrays is immutable. Once created, it never changes until the resource is destroyed. Inside and outside wgpu, the resources referred to by Ids which boil down to indices in the resource arrays with metadata.
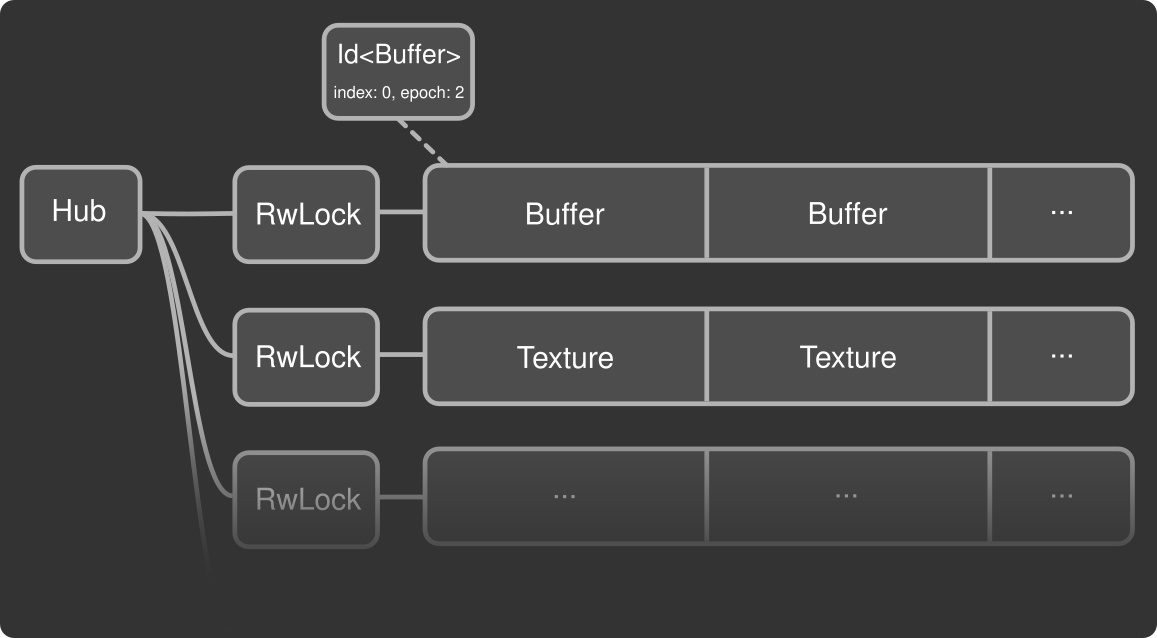
This should play well with parallel access of the data from multiple threads, right? Unfortunately adding and removing resources requires mutable access to these resource arrays. Which meant adding locks. Locks when adding or removing items, but also locks while reading from the data they contain. Locks everywhere, and locks that have to be held for a non-negligible duration. This caused a lot of lock contention and poor performance when wgpu is used on multiple threads.
Interestingly, wgpu also had to maintain internal reference counts to resources, to keep track of the dependencies between them (for example a bind group depends on the bindings it refers to). This reference counting was carried out manually, and rather error-prone.
The solution
“Arcanization”, as it names implies, was the process of moving resources behind atomic reference counted pointers (Arc<T>). Today the Hub still holds resource arrays, however these contain Arcs instead of the data directly. This lets us hold the locks for much shorter times - in a lot of cases only while cloning the arc - which can then be read from safely outside of the critical section. In addition, some areas of the code don’t need to hold locks once the reference has been extracted.
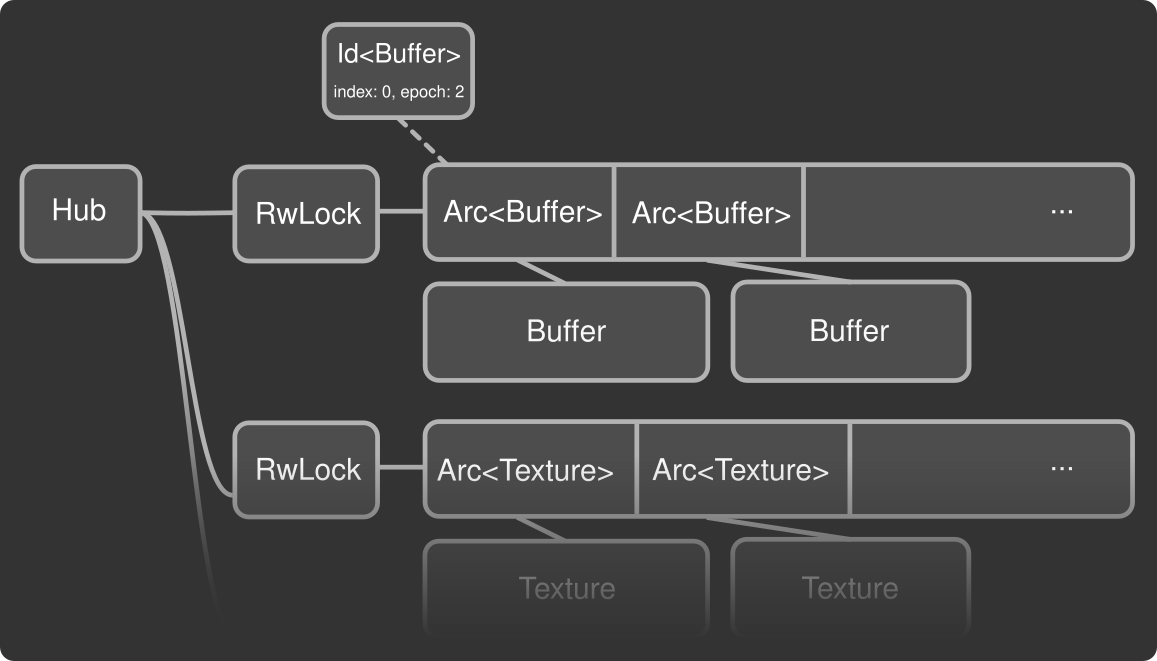
The result is much lower lock contention. If you use wgpu from multiple threads, this should significantly improve performance. Our friends in the bevy engine community noted that some very early testing (on an older revision of arcanization) showed that with arcanization, the encoding of shadow-related commands can run in parallel with the main passes, yielding 45% frame time reduction on a test scene (the famous bistro scene) compared to their single threaded configuration. Without arcanization, lock contention is too high to significantly improve performance.
In addition, wgpu’s internals are now simpler. This change lifted some restrictions and opens the door for further performance and ergonomics improvements.
wgpu 0.19
The next release featuring this work will be 0.19.0 which we expect to publish around January 17th. We made sure to merge the changes early in the release cycle to give ourselves as much time as we can to catch potential regressions.
This is an absolutely massive change and while we have and are testing as best we can, we do need help from everyone else. Please try updating your project to the latest wgpu and running it. Please report any issues you find!
What’s next?
Lifting RenderPass<'a> lifetime restrictions
If you have used wgpu, there is decent chance that you have had to work around the restrictions imposed by the 'rpass lifetime in a lot of RenderPass’s methods, such as set_bind_group, set_pipeline, and, set_vertex_buffer. The recent changes give us the opportunity to store Arcs where &'a references were previously needed which should let us remove these lifetime restrictions.
Internal improvements
There is ongoing work to ensure that buffer, textures, and devices can be destroyed safely while their handles are still alive. This is important for Firefox which uses wgpu_core as the basis for its WebGPU implementation. In the garbage-collected environment of javascript, the deallocation of resources is non-deterministic and can happen a long time after the program is done using the resources. While this in itself does not require arcanization, it gives us a better foundation to improve upon internal resource lifetime management.
Reference counting at the API level
So resources like buffers and textures are now internally reference counted, but the handles wgpu exposes are not. Could we potentially expose the reference counted resources more directly, avoiding going through the Hub? Most likely yes. That would be another fairly large project with important implications to wgpu_core’s recording infrastructure and how it integrates in Firefox. It won’t happen overnight, but that’s certainly something the wgpu maintainers would like to move towards.
Closing words
Changes of this scope and complexity take tremendous effort to realize, and take orders of magnitude more effort to push over the finish line. @gents83’s achievement here is truly outstanding. He poured an endless amount of time, effort, and patience into this work, which we now all benefit from, and deserves equally endless amounts of recognition for it.
Thanks @gents83!